Launch day – what happened to the website?
Liz: As you may recall, back on February 2 we launched a new product. This website buckled a little under the strain (as did some of our partners’ websites). At the time, we promised you a post about what happened here and how we dealt with it, with plenty of graphs. We like graphs.
Here’s Pete Stevens from Mythic Beasts, our hosts, to explain exactly what was going on. Over to you, Pete!
On Monday, the Raspberry Pi 2 was announced, and The Register’s predictions of global geekgasm proved to be about right. Slashdot, BBC News, global trending on Twitter and many other sources covering the story resulted in quite a lot of traffic. We saw 11 million page requests from over 700,000 unique IP addresses in our logs from Monday, around 6x the normal traffic load.
The Raspberry Pi website is hosted on WordPress using the WP Super Cache plugin. This plugin generally works very well, resulting in the vast majority of page requests being served from a static file, rather than hitting PHP and MySQL. The second major part of the site is the forums and the different parts of the site have wildly differing typical performance characteristics. In addition to this, the site is fronted by four load balancers which supply most of the downloads directly and scrub some malicious requests. We can cope with roughly:
| Cached WordPress | 160 pages / second |
|---|---|
| Non cached WordPress | 10 pages / second |
| Forum page | 10 pages / second |
| Maintenance page | at least 10,000 pages / second |
Back in 2012 for the original launch, we had a rather smaller server setup and we just put a maintenance page up and directed everyone to buy a Pi direct from Farnell or RS, both of whom had some trouble coping with the demand. We also launched at 6am GMT so that most of our potential customers would still be in bed, spreading the initial surge over several hours.
This time, being a larger organisation with coordination across multiple news outlets and press conferences, the launch time was fixed for 9am on Feb 2nd 2015 so everything would happen then, apart from the odd journalist with premature timing problems – you know who you are.
Morning folks! As you may have gathered if you’ve been on Twitter this morning, we’ve just launched Raspberry Pi 2! http://t.co/L999uza8wu
— Raspberry Pi (@Raspberry_Pi) February 2, 2015
Our initial plan was to leave the site up as normal, but set the maintenance page to be the launch announcement. That way if the launch overwhelmed things, everyone should see the announcement served direct from the load balancers and otherwise the site should function as normal. Plan B was to disable the forums, giving more resources to the main blog so people could comment there.
The Launch

It is a complete coincidence that our director Pete took off to go to this isolated beach in the tropics five minutes after the Raspberry Pi 2 launch.
At 9:00 the announcement went live. Within a few minutes traffic volumes on the site had increased by more than a factor of five and the forum users were starting to make comments and chatter to each other. The server load increased from its usual level of 2 to over 400 – we now had a massive queue of users waiting for page requests because all of the server CPU time was being taken generating those slow forum pages which starved the main blog of server time to deliver those fast cached pages. At this point our load balancers started to kick in and deliver to a large fraction of our site users the maintenance page containing the announcement – the fall back plan. This did annoy the forum and blog users who had posted comments and received the maintenance page back having just had their submission thrown away – sorry. During the day we did a little bit of tweaking to the server to improve throughput, removing the nf_conntrack in the firewall to free up CPU for page rendering, and changing the apache settings to queue earlier so people received either their request page or maintenance page more quickly.
We’ve temporarily disabled our forums to alleviate traffic to the main site. You can ask questions in the blog post comments! — Raspberry Pi (@Raspberry_Pi) February 2, 2015
Disabling the forums freed up lots of CPU time for the main page and gave us a mostly working site. Sometimes it’d deliver the maintenance page, but mostly people were receiving cached WordPress pages of the announcement and most of the comments were being accepted.
Super Cache not quite so super
Unfortunately, we were still seeing problems. The site would cope with the load happily for a good few minutes, and then suddenly have a load spike to the point where pages were not being generated fast enough. It appears that WP Super Cache wasn’t behaving exactly as intended. When someone posts a comment, Super Cache invalidates its cache of the corresponding page, and starts to rebuild a new one, but providing you have this option ticked…  …(we did), the now out-of-date cached page should continue to be served until it is overwritten by the newer version. After a while, we realised that the symptoms that we were seeing were entirely consistent with this not working correctly, and once you hit very high traffic levels this behaviour becomes critical. If cached versions are not served whilst the page is being rebuilt then subsequent requests will also trigger a rebuild and you spend more and more CPU time generating copies of the missing cached page which makes the rebuild take even longer so you have to build more copies each of which now takes even longer. Now we can build a ludicrously overly simple model of this with a short bit of perl and draw a graph of how long it takes to rebuild the main page based on hit rate – and it looks like this.
…(we did), the now out-of-date cached page should continue to be served until it is overwritten by the newer version. After a while, we realised that the symptoms that we were seeing were entirely consistent with this not working correctly, and once you hit very high traffic levels this behaviour becomes critical. If cached versions are not served whilst the page is being rebuilt then subsequent requests will also trigger a rebuild and you spend more and more CPU time generating copies of the missing cached page which makes the rebuild take even longer so you have to build more copies each of which now takes even longer. Now we can build a ludicrously overly simple model of this with a short bit of perl and draw a graph of how long it takes to rebuild the main page based on hit rate – and it looks like this. 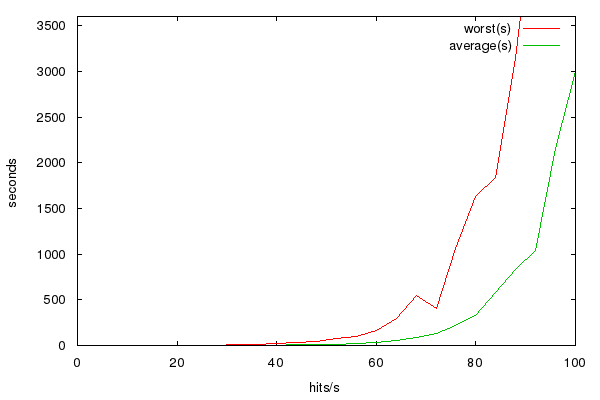 This tells us that performance reasonably suddenly falls off a cliff at around 60-70 hits/second. At 12 hits/sec (typical usage) a rebuild of the page completes in considerably under a second, at 40 hits/sec (very busy) it’s about 4s, at 60 hits/sec it’s 30s, at 80hits/sec it’s well over five minutes – the load balancers kick in and just display the maintenance page, and wait for the load to die down again before starting to serve traffic as normal again. We still don’t know exactly what the cause of this was, so either it’s something else with exactly the same symptoms, or this setting wasn’t working or was interacting badly with another plugin, but as soon as we’d figured out the issue, we implemented the sensible workaround; we put a rewrite hack in to serve the front page and announcement page completely statically, then created the page fresh once every five minutes from cron picking up all the newest comments. As if by magic the load returned to sensible levels although there was now a small delay on new comments appearing.
This tells us that performance reasonably suddenly falls off a cliff at around 60-70 hits/second. At 12 hits/sec (typical usage) a rebuild of the page completes in considerably under a second, at 40 hits/sec (very busy) it’s about 4s, at 60 hits/sec it’s 30s, at 80hits/sec it’s well over five minutes – the load balancers kick in and just display the maintenance page, and wait for the load to die down again before starting to serve traffic as normal again. We still don’t know exactly what the cause of this was, so either it’s something else with exactly the same symptoms, or this setting wasn’t working or was interacting badly with another plugin, but as soon as we’d figured out the issue, we implemented the sensible workaround; we put a rewrite hack in to serve the front page and announcement page completely statically, then created the page fresh once every five minutes from cron picking up all the newest comments. As if by magic the load returned to sensible levels although there was now a small delay on new comments appearing.
Re-enabling the forums
@Raspberry_Pi @Mythic_Beasts any idea when normal service will resume and we will be able to use the forums during the daytime? — Peter Green (@plugwash) February 3, 2015
With stable traffic levels, we turned the forums back on. And then immediately off again. They very quickly backed up the database server with connections, causing both the forums to cease working and the main website to run slowly. A little further investigation into the InnoDB parameters and we realised we had some contention on database locks, we reconfigured and this happened.
Our database server’s just fallen over. Rebooting – gradually! — Raspberry Pi (@Raspberry_Pi) February 4, 2015
Our company pedant points out that actually only the database server process fell over, and it needed restarted not rebooting. Cunningly, we’d managed to find a set of improved settings for InnoDB that allowed us to see all the tables in the database but not read any data out of them. A tiny bit of fiddling later and everything was happy.
The bandwidth graphs
We end up with a traffic graph that looks like this.  On the launch day it’s a bit lumpy, this is because when we’re serving the maintenance page nobody can get to the downloads page. Downloads of operating system images and NOOBS dominates the traffic graphs normally. Over the next few days the HTML volume starts dropping and the number of system downloads for newly purchased Raspberry Pis starts increasing rapidly. At this point were reminded of the work we did last year to build a fast distributed downloads setup and were rather thankful because we’re considerably beyond the traffic levels you can sanely serve from a single host.
On the launch day it’s a bit lumpy, this is because when we’re serving the maintenance page nobody can get to the downloads page. Downloads of operating system images and NOOBS dominates the traffic graphs normally. Over the next few days the HTML volume starts dropping and the number of system downloads for newly purchased Raspberry Pis starts increasing rapidly. At this point were reminded of the work we did last year to build a fast distributed downloads setup and were rather thankful because we’re considerably beyond the traffic levels you can sanely serve from a single host.
Could do a bit better
The launch of Raspberry Pi 2 was a closely guarded secret, and although we were told in advance, we didn’t have a lot of time to prepare for the increased traffic. There’s a few things we’d like to have improved and will be talking to with Raspberry Pi over the coming months. One is to upgrade the hardware adding some more cores and RAM to the setup. Whilst we’re doing this it would be sensible to look at splitting the parts of the site into different VMs so that the forums/database/Wordpress have some separation from each other and make it easier to scale things. It would have been really nice to have put our extremely secret test setup with HipHop Virtual Machine into production, but that’s not yet well enough tested for primetime although a seven-fold performance increase on page rendering certainly would be nice.
Schoolboy error
Talking with Ben Nuttall we realised that the stripped down minimal super fast maintenance page didn’t have analytics on it. So the difference between our stats of 11 million page requests and Ben’s of 1.5 million indicate how many people during the launch saw the static maintenance page rather than a WordPress generated page with comments. In hindsight putting analytics on the maintenance page would have been a really good idea. Not every http request which received the maintenance page was necessarily a request to see the launch, nor was each definitely a different visitor. Without detailed analytics that we don’t have, we can estimate the number of people who saw the announcement to be more than 1.5 million but less than 11 million.
Flaming, Bleeding Servers
Liz occasionally has slightly odd ideas about exactly how web-servers work:
Looks like we’re getting about 130 web requests per second on our site at the moment. The servers are, amazingly, not on fire (yet). — Raspberry Pi (@Raspberry_Pi) July 14, 2014

Now, much to her disappointment we don’t have any photographs of servers weeping blood or catching fire. [Liz interjects: it’s called METAPHOR, Pete.] But when we retire servers we like to give them a bit of a special send-off: here’s a server funeral, Mythic Beasts-style.





38 comments
Alex Eames (RasPi.TV)
Great post. Thanks Pete. It was great to see you at the weekend too. :)
Robin
Why not use GitHub pages for all your “static” content and the servers only for the forums and other dynamic content?
It might change your blog process a bit, but I don’t think it is possible to overload the CDN they have in place.
Pete Stevens
I’m not sure how that would help. We don’t really have any issues delivering static resources, it’s dynamic or rapidly changing ones that caused the problems which looks like a bad interaction with another wordpress plugin, or the comment moderation process and the supercache plugin. We will eventually run out of bandwidth for delivering downloads on the current configuration but we can trivially move more traffic to the Velocix CDN (currently we only push non EU traffic through them) if we need to. The current setup is quick enough to ship downloads of N00Bs at roughly the same rate that Pis come off the production line, but many people have pre-installed SD cards so we don’t need to do that many.
AndrewS
Nice to hear that NOOBS downloads are still in safe hands :-)
Pete Stevens
In a previous career I did have to deal with the infamous Dell 1650 servers that quite regularly caught fire. Setting the webserver on fire still wouldn’t be the oddest customer request we’ve ever received!
Dogsbody
At [large unnamed server vendor] we weren’t allowed to say that a server caught fire. We were told to say that the server had a “thermal event”!
Chris Evans
Very interesting post and I love the trebuchet/domino video:-)
Ton van Overbeek
Just curious what happened with the retired servers after the server castle was “destroyed” in the video?
Pete Stevens
They’ve mostly now been recycled or melted down. The disks went in the shredder and the shards melted. We had a request from an open source project to nab a few of them – they took twelve and managed to salvage eight 1U servers to form a build cluster.
Julian
Maybe you should look into hosting your site on Google or Amazon infrastructure. That way it would have been easy to scale when there was a surge in traffic to the website.
paddyg
Isn’t there some clever pun involving clouds and castles in the air. Maybe not.
Pete Stevens
Scaling on AWS or Google compute isn’t quite that simple and would involve some considerable rearchitecting of the site as it stands and we’re not yet confident all the plugins and parts of the site work well in a distributed setup. Mythic Beasts do have a test distributed setup which implements this (and HipHop VM for a free factor of five speed increase per server involved), but given the schedule it wasnt possible to roll it out in time for the launch.
Whilst I can’t speak directly for Raspberry Pi and their decision making process, a rough estimate would be the costs of running their website on Google or Amazon instead of the current setup with Mythic Beasts and Velocix donating considerable amounts of bandwidth would increase their costs by several hundreds of thousands of dollars per year, money which Mythic Beasts feel is better spent on educational resources. Certainly spending a very large amount of money in order not to understand how things work, seems somewhat opposed to the goals of the Raspberry Pi project
Nikos
Don’t get me wrong here, no flame intended, but this is typical 2000-ish. Instead of trying to come up with code that works faster and more efficient, we just throw in more resources to solve the problem…. are we solving it that way?
And, then, we are wondering why our kids do not learn coding correctly…
Pete Stevens
I don’t think anyone is going to hold up WordPress as a shiny example of beautiful efficient code. However, there’s a trade-off involved – no matter how much we built a hand optimised version of the Raspberry Pi site to run on a set of Pis, we’d still need around a hundred of them just to supply the bandwidth, 100Mbps just isn’t very much on a world wide scale. We’ve applied a certain amount of thought to the gigantic stack of stuff involving apache,mysql,php, wordpress and a whole set of plugins to improve performance by about a factor of 100 over the naive implementation. When we get HipHop VM into production we’ve hopefully got another factor of five or so. But eventually you get to a point where instead of optimising the code the pragmatic decision is to throw more hardware at the problem, and scale out with more machines.
Most web applications are crazily inefficient and use stacks more hardware than is sensible for the amount of useful work they do. Problem is smart programmers are expensive and computers are comparatively cheap so the pragmatic option is to throw hardware at it until the bills become so huge it’s worth investing developer time.
One day someone will come up with a charitable project that aims to teach a whole generation of people computing. If someone starts one, Mythic Beasts would love to be involved, donate loads of bandwidth to them and eventually employ the programmers the project generates.
Homer L. Hazel
Oh what a clever idea! Have a charity that is aimed at teaching computing to kids. I laughed out loud when I read that. Great! and I am glad you are involved! 8>)
Ken MacIver
Blade Fort demolition; as Homer Simpson or Fred Flintstone might say with the Buffaloes down at the Bowl
“STrrrrrriiiiikkkE”
Liz Upton
I had a great game when I was a kid called Crossbows and Catapults, where you’d build a little plastic fort and you’d each try to knock your opponents’ down with little rubber-band trebuchets. BRILLIANT game.
Pete Stevens
I didn’t, but my friend did and it was the most awesome game to play ever when I went around. Where do you think I stole the idea from!
G
As I am working close to the hardware it is most interesting to read about ‘the other’ side of computer usage. I have a masters degree in computing but that is now so old (and having my nose always close to the grindstone) there is a lot in the article that I can’t follow. A bit depressing but good to see we have come a long way since toggling octal switches on a PDP-11. Reminds me: have to look up if technology is really speeding up faster each generation or if just seems that way.
Łukasz Oleś
Did you consider switching to for example Disqus comments? It would allow you to use static pages or cached pages without a risk of regenerating cache. Comments are loaded asynchronously then.
Pete Stevens
Hindsight is of course a wonderful thing. We weren’t expecting the magic don’t-be-stupid cache flag not to work – once we knew what the problem was working around it was easy enough. Had we known in advance what the problem was we’d have fixed it before it happened.
I’m not a member of RaspberryPi and can’t speak for the foundation, but I speculate that the contract terms of Disqus might be an issue – for example the privacy policy, selling data to advertisers, disallowing under 13s from using the service aimed at educating children, that sort of thing. You’d have to find some legal people who can speak on behalf of the Foundation for a proper answer though.
Dougie
And for Raspberry Pi 3 you’ll be running everything on Raspberry Pi 2s. We don’t need no stinking 1U or 2U rack mounted servers.
Pete Stevens
I would love to do that but it’s not going to fit in 2U. We’re going to need 2U of switches to put in enough 100Mbps interfaces to keep up for starters….
Jim Manley
Great recap Pete! As Liz and Eben will tell you, I have quite a long and accurate history of predicting the future of the demand for all things Pi going back to before they were offered to the public for $35 (the auction-priced beta boards don’t count), including Net resources (notice I didn’t say just web resources – we know that there’s a whole lot more going on in this problem space than http/https packets). I’m going to ask a question and then time how long it takes to get a response, and anything less than seconds means the test has been failed. So, get ready, get set, and go!
What are you using to realistically test both your current and projected infrastructure? If you had to think about that, or you just don’t have an answer, you might want to start down that path. For starters at absolutely no cost other than blog and forum posts, you could ask the Pi community to simulate what it would be like if, say, the Foundation announced that the Pi 3 is now available for sale, with 16 cores, 100 GB of RAM, a 6 GHz clock speed, a 10 TBps fiber interface … for $35 (that oughta put the “I wanna” types back in their seats – oh, no, I didn’t mean to spill the beans Eben and Liz, please don’t cut me off!!! Well, at least I didn’t say when it was coming :) I think we could do a pretty good job of helping you make sure that Murphy has a tougher time tipping the site over during the next real boffo announcement.
Prior to a real-world test, however, and at a slightly higher cost than blog/forum posts, I’d be very surprised if you weren’t aware that there is plenty of very effective software Out There (much of it open-source) for automating the testing of such resources. I dare to say that a pretty interesting experiment would be to turn our community’s Pii into a giant DDOS test rig, where everyone would be able to download and run some code that would generate traffic using the various protocols and request/response packet collections associated with these major events, all under your remote control. Obviously, you could start small with selected participants and then gradually scale up until the blood, sweat, and tears start flowing.
Of course, the real problem is WordPress, but I do understand the legacy of the decision to start and continue with that. I’ll bet you that the Pi community could come up with something much, much better though, and I think it’s time we should seriously start developing that Next Next Thing. I think it’s fascinating (as Spock would say) that the size of the Pi market and community (which are two very different things, as the Pi wanna-be types don’t seem to understand) are growing large and fast enough that Google prospective employee interview questions are becoming necessary (they make a very big deal about asking prospects to determine O(…) magnitudes for postulated problems in addition to the more typical computing syntactical trivia, e.g., programming language oddities).
Let’s talk, or at least type :D
Pete Stevens
We test the website setup on hundreds of thousands of visitors every day, sometimes even millions. When we did the look and feel upgrade we had some trouble, because we had some inefficient code in our 404 page – now that’s a tricky one to test in advance.
Ultimately it’s a questions of resources and guessing. We carefully checked our config to make sure that cache rebuilds wouldn’t be a problem and we had O(n) performance with number of vistors in the site. It’s only when a cache deletion event occurs that we have O(n^lots) performance and we’d carefully checked that wouldn’t happen.
Maybe Pi community probably could come up with something better than WordPress and if they did that’d be great, although WordPress is a fantastic free tool for building a really effective community. But alternatively the Pi community could carry on flying things to space, making duelling pianos, synthesisers, games consoles and all the other myriad amazing things they make instead. Similarly when you say ‘testing at no cost’, actually it’s tremendously expensive – getting hundreds of thousands of people to our website for an hour means that hundreds of thousands of hours of Pi development projects don’t get done, kids don’t learn code, traffic lights don’t get soldered and Babbage bears don’t get sent to the moon.
It’s unfortunate that for a short time the community had to stop chatting and being excited about the Pi 2, while the rest of the world discovered amazing the Raspberry Pi is. And now we’re routinely seeing twice as much traffic so that’s twice as many people we’re now getting too, which is amazing and not what we predicted, we thought the excitement would wear off fairly quickly.
But since I’ve got the offer of someone with a long and accurate history of predicting demand some future numbers would be really helpful for my planning – assuming there’s a Raspberry Pi 3 announcement in the next two years, could you tell me to one significant figure how many visitors will turn up at the site in the first day, how many requests we’ll have in the busiest minute, what fraction of those visitors will leave a comment on the blog and how many people will leave a comment on the forum, how many forum pages will be read and how many searches will be done on the site and/or forums.
Dutch_Master
What a brilliant riposte!
Anyway, I too was caught up in the frenzy trying to access the forums and getting the static announcement page. Very nice to for once hear the true story behind it, something not many ISP’s share publicly. Hats off for that Sir!
Finally, may I suggest recycling the cases of disposed 1U and 2U servers by gutting their innards (and making sure those are properly disposed off), retaining the actual case and putting new hardware in them (that is: new PSU, main board, drives, processor, memory, etc) would make Mythic Beasts look greener* ;-)
*as in: environmentally friendly greener ;-P
Ben Nuttall
*applaud*
Ralph Corderoy
Hi Pete,
So the thundering-herd problem is an architecture issue, not sure you can easily do much about that. There are caches that are aware of it and set just one worker labouring, e.g. Brad Fitzpatrick’s groupcache, but that’s of little help to the WordPress blog and forum. :-)
HHVM sounds like an improvement. And the speed improvement of your tests show bytecode interpretation is an issue, obviously. But has any investigation into the bottlenecks of the PHP source’s logic, or its use of MySQL, been done? Just a bit of a skim shows the code’s fairly naff, e.g. comment_type() can end up calling __(), i.e. translate() for strings it never uses because only one of the three is ever required. And translate() then calls apply_filters() which does its work of looking for suitable callback hooks to call. All for it to be discarded. Similarly, looking at MySQL’s workload might show up queries that can be easily improved, or merged into one rather than three.
Just thinking, the Foundation have put effort into speeding up code for good Pi 1 performance, perhaps they should do the same for their WordPress installation and its blog comments, if they’re stuck with it.
Has consideration been given to out-sourcing the comments, e.g. to Disqus, which is possible with WordPress. That would leave Disqus to cope with the load, which is their purpose, and each user’s browser to shoulder the workload of rendering the comments. Each new comment no longer invalidates the cache of the blog post.
Pete Stevens
I’m sure the WordPress team look at the WordPress code and balance up performance, maintainability and other such things. As the guy who kicks the servers I don’t get to speak for the foundation. But if I were in charge (queue maniacal laughing) I’d probably conclude that I’d be better off spending some money on faster servers for the website and putting my developer resources into making code that runs on the Pi quicker. It’s a choice between optimising code that runs on a small handful of machines, or millions (with any luck, soon to be tens of millions).
Whilst my inner techie would love to make WordPress super swish and optimist, my evil accountant twin says spend some money on bog-standard fast servers and optimise the code running on the Pi.
Ralph Corderoy
Hi Pete,
I’m sure the WordPress team look at the WordPress code and balance up performance, maintainability and other such things.
No, they don’t. Their aim is the most generic framework that can be configured and adapted through filters, etc., to meet a wide range of users’ needs. They want breadth of appeal for market share, not performance for the top 0.01% of installations. Performance is not a primary concern as most users don’t have much traffic and a fragment of a modern server easily copes. They’d rather add another layer of code to provide a new feature, knowing today’s hardware is faster than yesterday’s and gives them the budget.
I’d be better off spending some money on faster servers for the website
That won’t help because of the thundering herd architectural problem unless the unit of work, producing the blog post HTML with up to date comments, is made much faster than now so the herd can all be watered.
Martin Grønholdt
Have you looked in to using https://www.varnish-cache.org? As far as I can tell the Super Cache thingy runs in PHP, varnish should be pretty optimized and runs natively.
Pete Stevens
If we’d used varnish, then one of two things happens,
(a) we serve cached content much longer than we need to so people see old versions of the page
(b) we invalidate the cache too quickly and exactly the same problem bites us
(c) both
What a smart person would do at this point is realise that if there was an alternative caching platform available that is fast enough, is aware of the state of wordpress so knows when to invalidate the cache, and has a magic tickbox feature so that it’s supposed to serve cached pages while it rebuilds the cache. That product exists, it’s called Supercache and that’s why we use it. It’s a shame that it seems a bug in the rebuilding process caused it not to work as well as it should have done.
Cache invalidation is a hard problem.
war59312
Cloudflare!
Would have saved you.
Please? Would make everything faster and free SSL. :D
Pete Stevens
Cloudflare would have saved us … and MongoDB is webscale.
Seriously did you even read the post? If your site is down Cloudflare serves up a cached holding page. That’s exactly what our load balancing front ends do, except we had the freedom to make it a super fast holding page containing the announcement before we updated the site.
war59312
And switch over to Nginx while you are at it.
Then enable HHVM like you mentioned. I’m using both on production site. Only 20,000 daily unique users. :)
Pete Stevens
Nginx / HHVM was slightly slower than Apache / HHVM in our testing, so it’s not immediately obvious that spending a bunch of time converting our configuration from Apache to Nginx is a sensible use of money.
However, I now owe Ben Nuttall a beer, I’d bet him that within an hour of this post going up someone would have told us that Nginx would have solved all of our problems and it’s taken several whole days to get there!
Tim Smith
Stock setups NGINX and Apache are almost identical in performance. I inherited a popular WordPress site that was experiencing scalability issues and I spent quite a bit of time exploring how to better scale the site.
1) PHP-FPM on Nginx vs. Apache. We saw a very large performance increase there. There’s some very excellent WordPress focused benchmarks out there showing the gains you might expect.
2) Pull in the very latest PHP. There’s been huge improvements in PHP lately especially the Zend OPcache caching engine. Stock Trusty PHP is much faster than Precise and there’s PPAs with the latest (5.6) that performs even better
3) Offload your static content to a CDN. There’s plenty of plugins to do this automatically. I use the “Amazon S3 and CloudFront” and “Amazon Web Services” plugins. Super easy to setup. Cost is next to nothing and load times see a huge improvement when you’re serving content locally.
4) Nginx microcaching. Nginx itself does a great job of caching content at the webserver level. There’s a plugin for wordpress that handles the invalidation of content automatically when page content changes. If you’re in a pinch you can turn that off and crank up the cache expiration time. Comments will be a bit stale, but performance will scream.
Final comment is prepping for a big event. Our site often sees large traffic spikes when things blow up on social media. In a short period of time traffic might go up 10X. We’re hosted in Amazon and that allows us to easily scale with traffic spikes if need be. I can double or triple the nodes serving our content very rapidly since the systems are configured with Chef. We use Amazon’s hosted MySQL (RDS) which can easily scale up / down. Adding 25 nodes and tripling our database capacity can be done in about 15 minutes. With an autoscaling group and prebaked AMIs you can cut that down to just a few minutes.
Pete Stevens
HHVM looks like the most effective software step. We’ve benchmarked and partly tested it, but weren’t quite brave enough to put it into production before the launch.
It’s fair to say that it would be somewhat more expensive for the foundation to host on Amazon than their current setup – currently we’re running a single large server and a handful of front-ends and shipping a substantial fraction of a PB of traffic on a monthly basis. I’ve never properly worked out how much it would cost to run their site within Amazon, but it’s considerably over $10,000 per month, probably less than $100,000 though, and to be honest that money is better spent on educating kids than rescuing Apollo engines from the bottom of the sea, cool though that may be.
But basically, all our problems stemmed from #4. We thought we were correctly set up to do exactly what you suggest, so that we’d always serve a cached page until the replacement page had been put into the cache. Unfortunately in practice that didn’t work out as smoothly as it should and we had to implement a work-around once we’d found the problem. Sadly as we already knew this wasn’t the issue it took quite some persuading to believe that it was.
Plus as an educational website our message isn’t really “Don’t understand anything technical, outsource it all to the cloud” :-)
+1 point though for being practically the first person ever, to spot that basic webserver performance isn’t really an issue. Three years of repeatedly explaining it in the comments and finally someone has paid attention!
Comments are closed